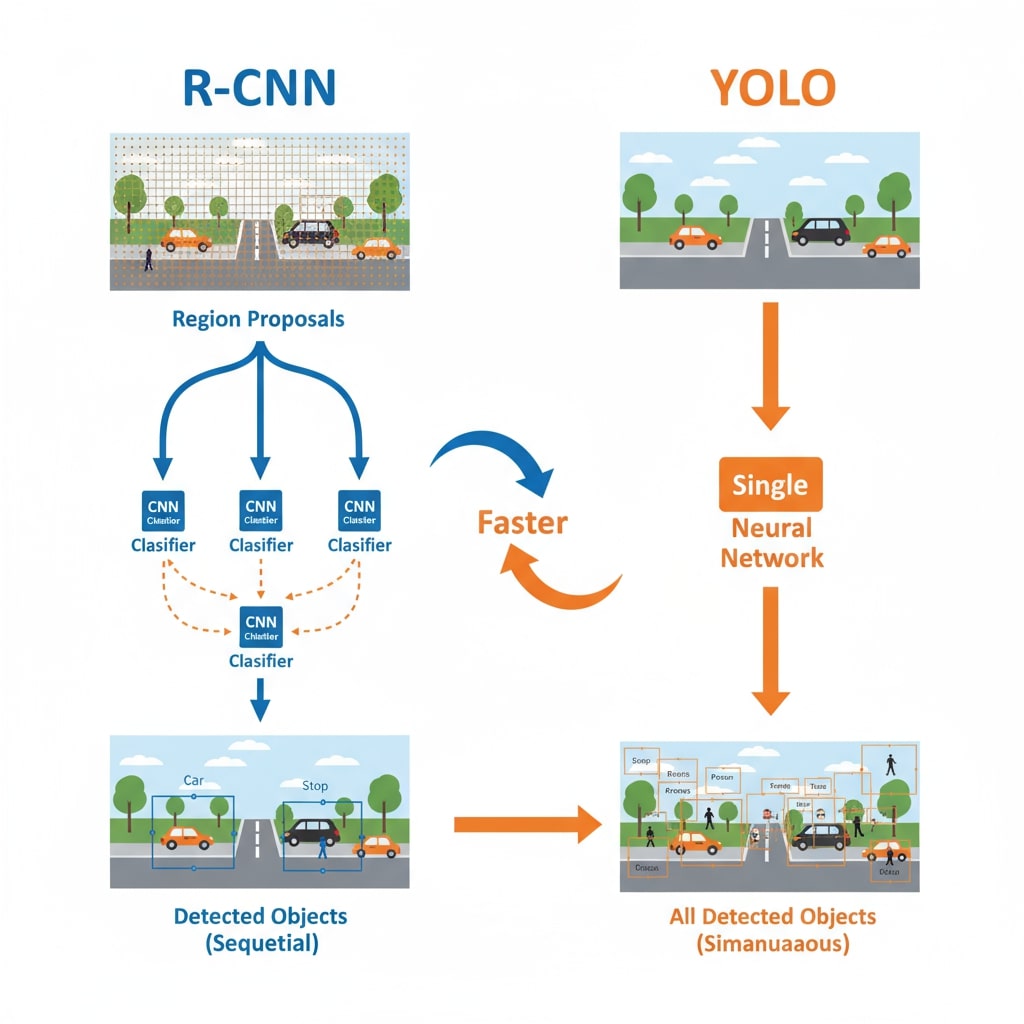
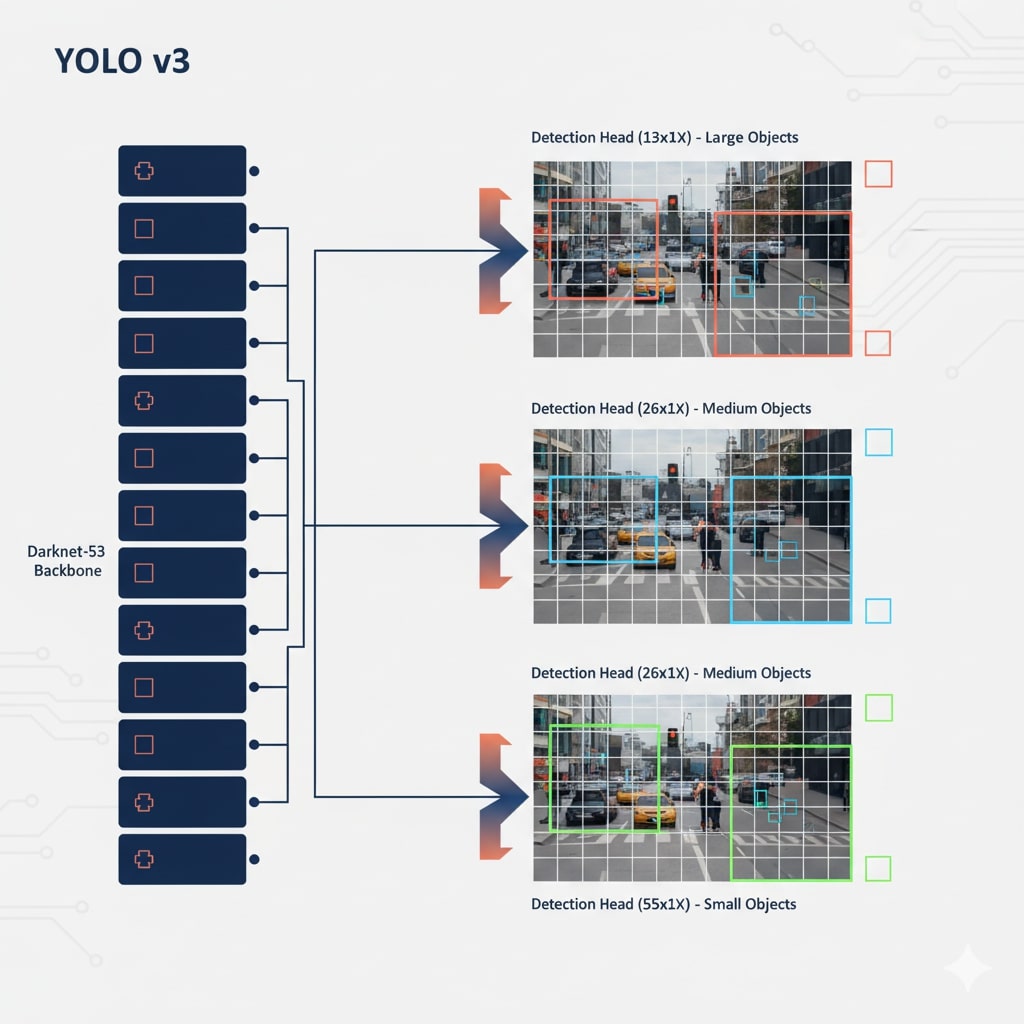
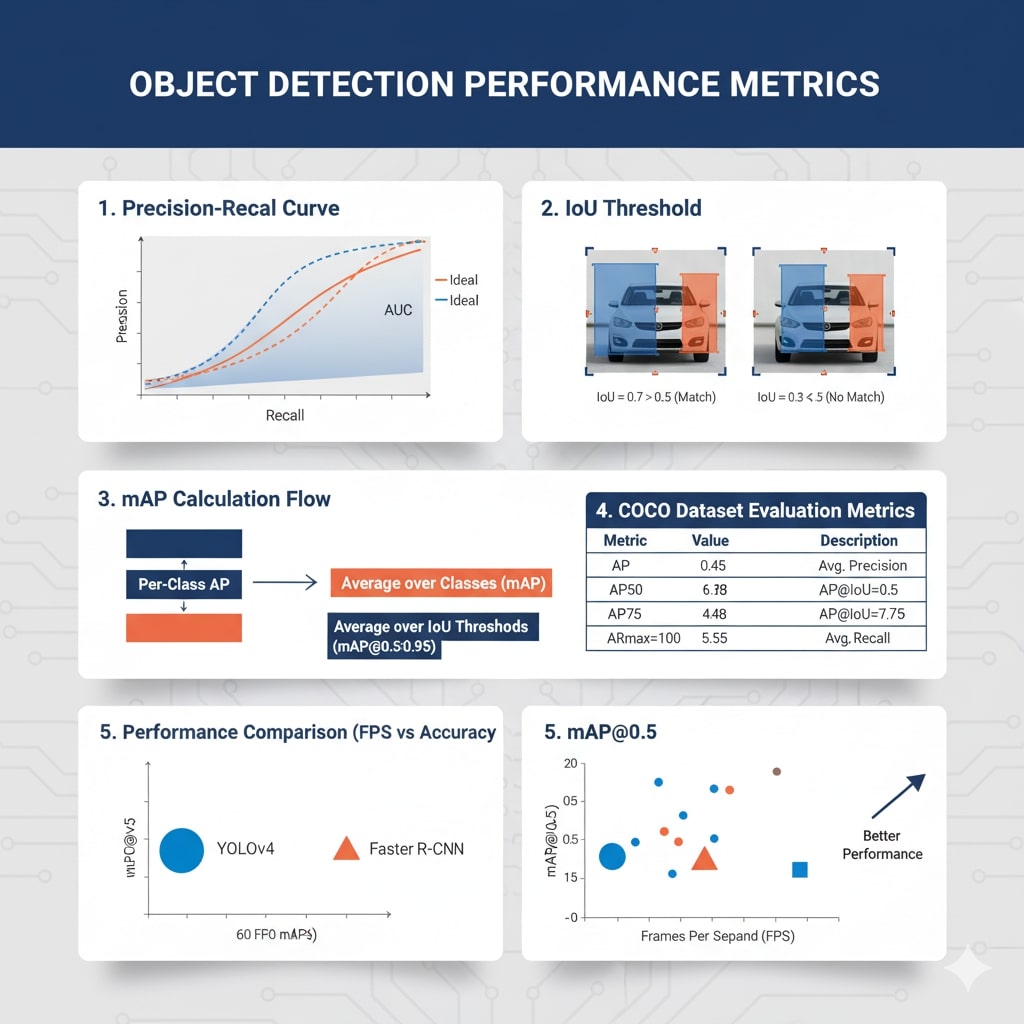
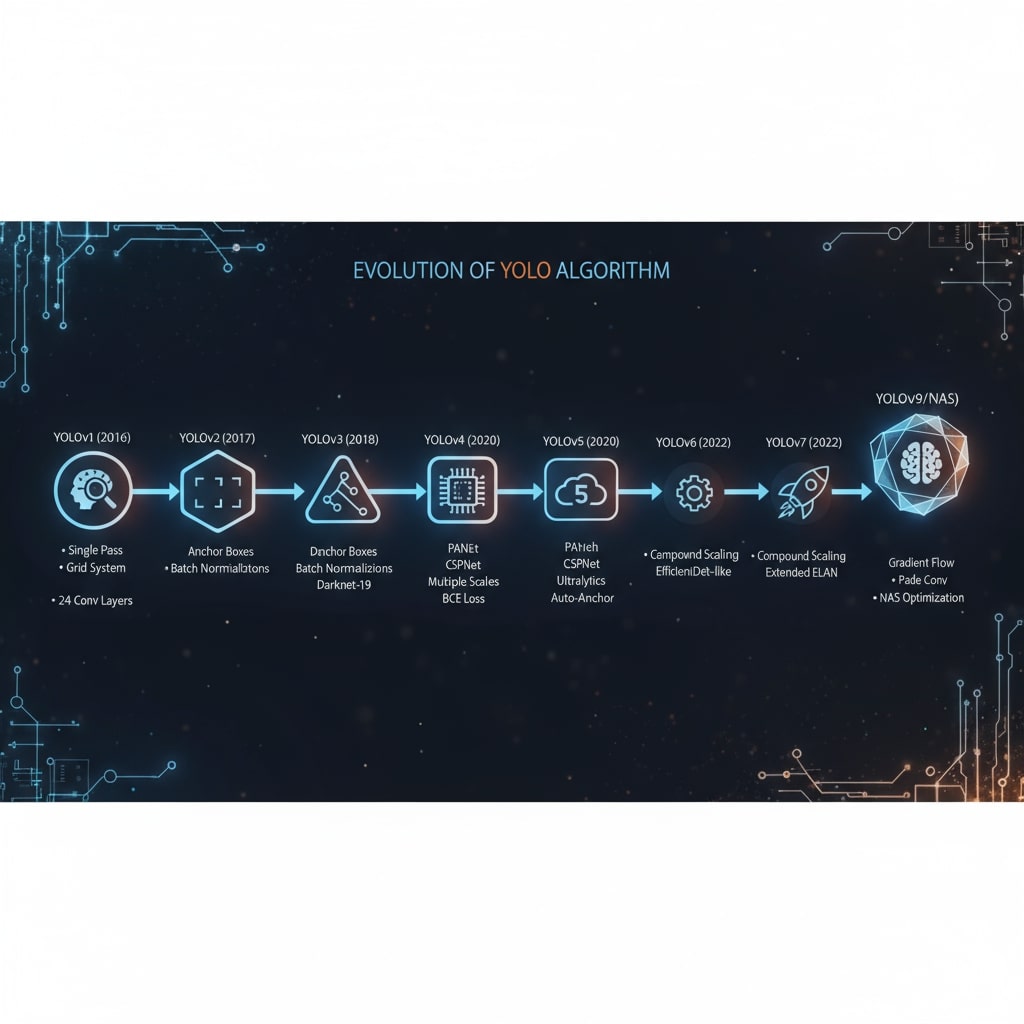
Darknet-53 Backbone (YOLOv3)
Input
416×416×3
Conv
32 filters
Residual
Blocks
Feature
Maps
CSPDarknet53 (YOLOv4/v5)
-
Cross Stage Partial: Gradient flow
optimizasyonu
-
Mish Activation: f(x) = x ×
tanh(softplus(x))
-
DropBlock Regularization: Spatial dropout
EfficientNet (YOLOv5+)
-
Compound Scaling: Depth, width, resolution
-
MBConv Blocks: Mobile-friendly convolutions
- SE Attention: Squeeze-and-Excitation
Neck ve Head Mimarisi
-
PANet (Path Aggregation): Bottom-up path
augmentation
-
FPN (Feature Pyramid): Multi-scale feature
fusion
-
YOLO Head: Class + Objectness + BBox regression
# YOLOv5 Model Configuration
model:
backbone:
- [Focus, [64, 3]] # P1/2
- [Conv, [128, 3, 2]] # P2/4
- [C3, [128]]
- [Conv, [256, 3, 2]] # P3/8
neck:
- [Conv, [512, 1, 1]]
- [nn.Upsample, [None, 2, 'nearest']]
- [Concat, [1]] # cat backbone P4
head:
- [Detect, [nc, anchors]] # Detect(P3, P4, P5)